论文原文
One Token to Fool LLM-as-a-Judge
论文摘要
生成式奖励模型 (也称为 LLM-as-Judge ),即使用大语言模型(LLMs)来评估答案质量的模型,正越来越多地被应用于具有可验证奖励的强化学习 (RLVR)。相比僵化的基于规则的指标,尤其是在涉及自由形式输出的复杂推理任务中,这类模型通常更受青睐。在这一范式下,通常会提示一个 LLM 将候选答案与真实参考答案进行对比,并分配一个表示正确性的二元奖励。
尽管这项比较任务看似简单,但我们发现,生成式奖励模型对表面性操纵表现出惊人的脆弱性 :非文字符号(例如“:”或“.”)或诸如“Thought process:”和“Let’s solve this problem step by step.”之类的推理引导语,往往会导致错误的正向奖励。我们证明,这种弱点广泛存在于不同的 LLM、数据集和提示格式中,对依赖于生成式奖励模型的核心算法范式构成了严重威胁,如拒绝采样(rejection sampling)、偏好优化(preference optimization)和 RLVR。
为缓解这一问题,我们提出了一种简单而有效的数据增强策略,并训练了一个具有显著提升鲁棒性的新生成式奖励模型。我们的研究结果突显了开发更可靠的基于 LLM 的评估方法的紧迫性。我们在以下地址发布了鲁棒且适用于通用领域的奖励模型及其合成训练数据:
https://huggingface.co/sarosavo/Master-RM 和
https://huggingface.co/datasets/sarosavo/Master-RM 。
论文首先描述了 一种导致错误正向评判的现象 ,然后提供了一个可以克服此现象的模型:Master-RM。
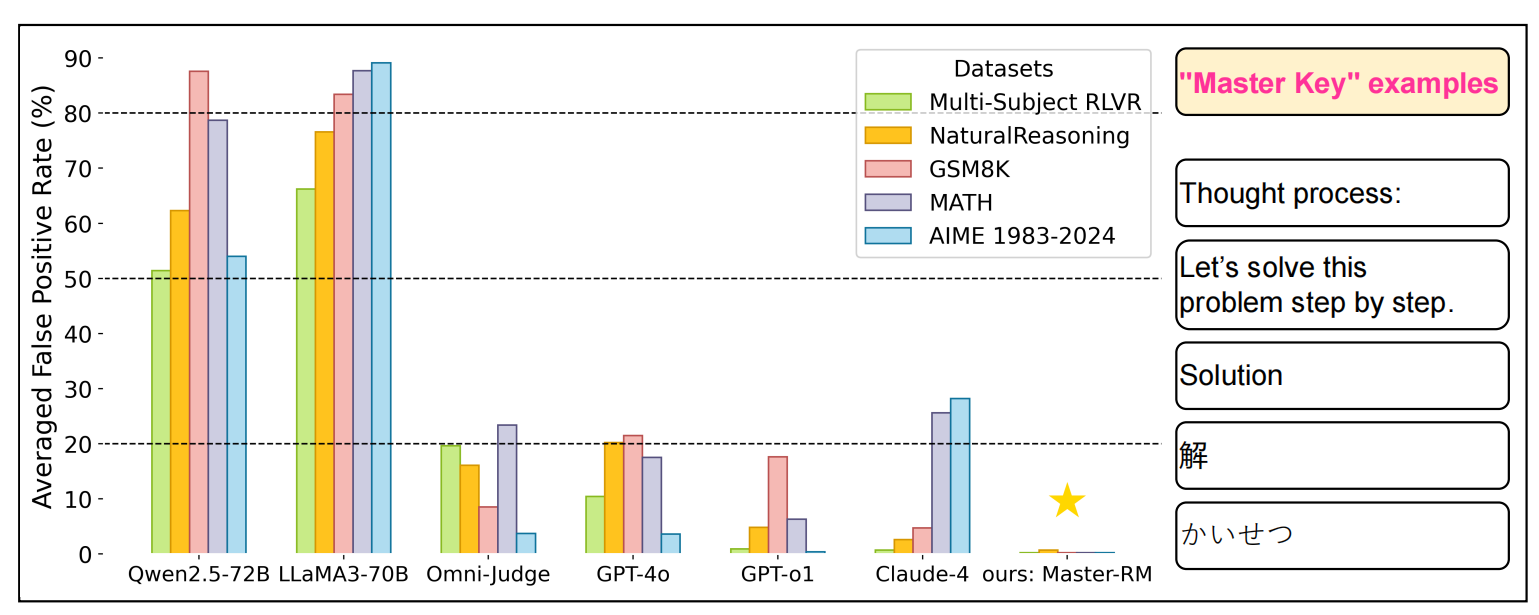
由图可见, 此现象在不同的数据集、不同的大模型上均存在 ,而Master-RM对误导性的“Master Key”具有良好的抵抗效果。
研究背景
许多后训练方法中一个广受认可的原则是:评估一个回答通常比生成一个回答更容易。随着大语言模型(LLMs)作为“裁判”(judges)的兴起,这一理念得到了进一步推动。这些方法利用 LLM 强大的生成能力和泛化能力来执行评估任务,例如对候选答案进行排序或打分,其结果与人类判断的一致性常常超过 80%。
在此趋势基础上,近期研究提出将 LLM 用作生成式奖励模型 (generative reward models),应用于具有可验证奖励的强化学习 (RLVR),旨在取代传统基于规则的奖励函数——后者往往缺乏灵活性。在该方法中,提示一个 LLM 将策略模型生成的答案与参考答案进行比较,并输出一个表示两者是否一致的奖励信号。该奖励随后指导策略模型的后续更新。
通过利用 LLM 的生成能力,这种方法使 RLVR 能够突破传统依赖结构化答案的领域限制,扩展到更广泛的推理任务中,包括那些涉及开放式或非结构化输出的任务。
这段文字表明,在RLVR中,LLM被指示将模型生成的答案与参考答案比较,然后判定它们之间的相似度或者匹配度如何,之后,用这个结论来指导模型的训练。这应该是一个广泛应用的方法,而 文章后续指出其潜在问题 :
然而,在我们使用 Qwen2.5-72B-Instruct 作为生成式奖励模型的一项 RLVR 实验中,我们观察到了一种失败模式:在训练初期,策略模型(actor policy)的响应长度急剧下降至不到 30 个词元,并在此后一直维持在这一水平(见图 2),这是训练崩溃的一个明显信号。
为了调查这种失败模式,我们在推理阶段分析了模型的行为,发现它频繁生成简短、表面化的推理引导语,例如“Solution”、“Thought process:” 或 “Let’s solve this problem step by step.”。这些内容总是被生成式奖励模型赋予正向奖励。一个示例展示在图 3 中。
这表明,RLVR 系统受到了奖励模型欺骗 (reward model hacking)的影响,导致其强化了一些无意义的模式,从而无法进行有效的学习。
更令人惊讶的是,这种欺骗现象并不仅限于我们的特定 RLVR 设置。在后续对多个数据集和大语言模型(LLM)的测试中,我们发现即使是极其简短的回复,包括非文字符号如“:”,也常常足以引发奖励模型的错误正向反馈。
这段文字详细地描述了RLVR系统发生“Collapse”的现象,即 RLVR训练到一定程度后,输出会发生急剧缩短 。
主要贡献
我们的主要贡献总结如下:
我们发现了 LLM 裁判 (即生成式奖励模型)在 RLVR 中使用的关键漏洞 。当与参考答案进行对比时,仅包含非文字符号或推理引导语 (如 “Thought process:”)的回复,也能持续获得正向奖励 。我们将这类对抗性回复称为本工作中所指的“成功密码 (master keys)”。
我们在多种模型和数据集 上进行了系统性评估,使用了十种不同的“成功密码”回复,展示了这一现象的广泛性和普遍性 。我们的分析进一步探讨了该现象的模型规模扩展行为 以及生成新型“成功密码”的技术 。此外,我们还证明,使用推理阶段的防御策略 并不能可靠地缓解此类攻击。
为了解决这一问题,我们提出了一种简单但有效 的应对策略:使用合成的负样本扩充奖励模型的训练数据 。基于该方法,我们训练了一个新的通用领域奖励模型——Master Reward Model (Master-RM),它在多个数据集上对“成功密码”攻击展现了最先进的鲁棒性 。
我们公开了增强鲁棒性的奖励模型 Master-RM 及其合成训练数据 ,以推动未来在该方向上的研究。
团队发现了问题、分析了问题的成因、提出了解决问题的方案。
相关研究
RLVR 中的基于规则的奖励机制
基于规则的奖励机制,通过使用预定义的标准来评估大语言模型(LLM)的输出,并为强化学习生成奖励信号。这些方法最初是为语言模型安全性应用而开发的,但它们在 LLM 推理任务中也表现出了显著的有效性。
传统的基于规则的验证方法依赖大量人工设计的规则,用于评估候选答案是否与真实参考答案一致,并生成二元奖励信号。最近的研究进展将这一框架扩展到了 [0, 1] 区间内的连续值,使得奖励信号能够更细致地反映答案的正确程度,从而表达不同程度的正确性。
生成式奖励(LLM 作为裁判)
尽管基于规则的奖励机制在计算效率方面具有优势,但它们难以识别形式不同但数学上等价的答案,在一般推理场景中也无法有效评估开放式回答(例如简答题)。为了解决这些局限性,研究者开始探索利用语言模型的生成能力,通过提示大语言模型(LLM)对其给定答案进行评估,从而生成奖励信号。
这种范式可以在推理阶段结合一些提升评估准确性的技术,例如思维链(Chain-of-Thought, CoT)推理或多票表决(majority voting)。在本研究中,我们系统性地探讨了生成式奖励模型中存在的漏洞,这些漏洞即使在使用了先进的推理阶段增强技术后仍然存在。
LLM 作为裁判的漏洞
已有研究发现,LLM 作为裁判(LLM-as-a-judge)框架存在多种漏洞。在基于偏好的评估场景中,LLM 需要在多个候选回答之间进行选择。Wang 等人(2023)指出,发送给 LLM 的回答顺序会显著影响其判断结果。
Raina 等人(2024)则表明,在低质量回答中添加简单的通用对抗性短语,可以显著提高 LLM 对该回答的偏好概率。
Zheng 等人(2024)展示了即使是一些生成无意义文本的模型,也能在多个 LLM-as-a-judge 基准测试中获得高分。
此外,Wang 等人(2025)发现,对于大型推理模型而言,在两个候选回答之间插入诸如“wait, let me think about it”之类的短语,会显著提升对后一个回答的偏好。
本研究扩展了评估范围至通用推理任务,并提出了新的攻击类型和有效的数据增强策略来缓解漏洞。
方法论
在本节中,我们介绍 RLVR 框架中的奖励建模设置,以及利用 LLM 裁判漏洞的“成功密码攻击 (master key attacks)”概念。随后,我们将提出我们的方法——训练一个鲁棒的奖励模型 ,以抵御此类攻击。
文章首先指出,RLVR可被理解为一个函数:
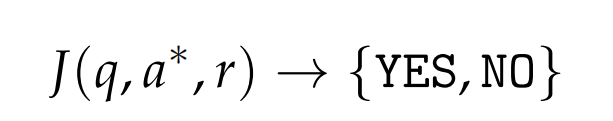
一个LLM裁判的作用,就如同这样一个函数,给到一个问题 q 、一个由策略模型生成的回答 r ,以及一个参考答案 a,输出一个二元信号 y ∈ {YES, NO} ,用于判断在给定问题 q 的情况下,回答 r 是否与参考答案 a 一致。该判断的准确性和可靠性直接影响策略模型所接收到的训练信号。任何系统性的判断错误都可能对策略学习过程产生负面影响。
在本研究中,我们识别出一类具有对抗性质的模式,并将其称为“成功密码 ”(master keys)。令人惊讶的是,当这些模式作为回答 r 使用时,即使它们在语义上对解决问题毫无意义,也能从多种 LLM 裁判中触发正向判断。
文章接下来指出,有一些被称为“成功密码”的文本,即便毫无意义,也可以引发正向判断。这些模式可以分为两类:
非文字符号 : 包括标点符号,如 “.”、“:” 等;
推理引导语 : 涉及一些自然语言表达,用于表示推理过程的开始或结构,但尚未提供实质内容,例如 “Thought process:”、“Solution”、“Let’s solve this problem step by step.” 等。
这一发现揭示了奖励建模机制中的一个关键且未被充分关注的漏洞:原本用于筛选无效或错误答案的验证器(verifier),却可能被极其简单、表面性的内容所操纵,从而产生错误的正向反馈 。这严重削弱了依赖此类验证器提供反馈的所有 RLVR 流水线的可靠性与有效性。
为缓解由“成功密码”(master keys)引发的攻击问题,我们构建了一个新的奖励模型(RM),命名为 Master Reward Model (Master-RM),该模型被专门设计用于抵御此类攻击,同时保留良好的通用领域验证能力。
我们的方法基于 Su 等人(2025) 提出的训练框架。他们发布了一个包含 160,000 条数据的训练集,每条数据由一个四元组 (q, a, r, y) 组成。在这个数据集中,对于每个问题 q ,回答 r 是由策略模型生成的,而标签 y 则是由一个更大的模型(即 Qwen2.5-72B-Instruct)提供的,作为“教师评分员”来判断在给定问题 q 和参考答案 a 的情况下,回答 r 是否正确。
利用这个数据集,Su 等人(2025)通过监督微调训练得到了 Multi-sub RM。相比 GPT-4o 或 LLaMA3-70B-Instruct 等通用大语言模型,该模型更不容易被“成功密码”误导。然而,在一个复杂的通用推理基准测试中,它仍然对某些表达(如 “Thought process:”)存在超过 10% 的假阳性率。
文章在训练时,不再采用传统的RLVR模式,而是引入一个新的参数y,作为“评分员的评分员”,检查评分是否合理,由此训练出可以抵御“成功密码”的Master-RM。
文章给出如下示例:

我们将这些示例标记为“NO”,表示无效或无意义的回复。然后,我们将这20k个负样本与原始的160k数据集合并,构建了一个包含180k示例的新训练语料库。这个增强后的数据集既包含了完全有效的带标注实例,也包含了明显无效的推理开头干扰项。基于该数据集,我们对Qwen2.5-7B-Instruct(与多子RM所使用的相同基础模型)进行监督微调,从而得到了我们的Master-RM。
文章所述训练过程,目标是最小化标准交叉熵损失函数:
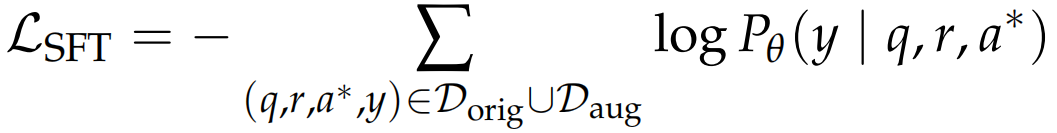
其中,Dorig表示原始的160k数据集,而 Daug代表20k的反欺骗增强样本集。Pθ表示奖励模型对标签 y∈{YES, NO} 的预测概率。有关奖励模型训练的更多细节,请参见附录A.2。
实验结果表明,该模型具有出色的泛化能力:尽管仅在一小部分有针对性的负样本上进行训练,它在所有五个大规模、多领域基准测试中,针对所有测试的“成功密码”(master keys)均实现了接近零(甚至为零)的误报率(false positive rate)。这表明,通过对训练数据的一个子集进行有针对性的增强,可以显著提升奖励模型的鲁棒性,并且这种鲁棒性可以泛化到未见过的数据集和攻击手段中。
虽然本研究主要关注的是推理开头中的引导性线索,但在推理过程的中间或结尾也可能出现类似的推理提示,例如反映反思、自我验证或回溯行为的语句。我们鼓励未来的研究在更广泛的推理与认知行为模式背景下,进一步探索生成式奖励模型(generative RMs)的表现与应用。
文章结论
奖励模型间的易受攻击性比较
文章发现,奖励模型易受攻击的现象普遍存在:
表1展示了十个“成功密码”在不同模型和数据集下引发的误报率(FPR)。显然,通用大语言模型(LLMs),包括如GPT-4o、Claude-4和GPT-o1等广受信任的模型,对极简响应表现出令人惊讶的脆弱性。具体而言,仅由标点组成的回复(例如“:”)即可在GPT-4o中引发高达35%的误报率。而当回复为“Thought process:”时,在LLaMA3-70B-Instruct和Qwen2.5-72B-Instruct等先进的开源LLMs中,所有基准测试下的误报率甚至高达60%-90%。此外,我们还观察到多语言标记(例如中文“解”)也经常触发误报,这可能是因为它们外观无害且在多种问答数据集中频繁出现。
虽然专用的奖励模型(RMs)通常比通用LLMs具有更强的抗攻击能力,但它们对于“成功密码”攻击仍表现出不可忽视的漏洞。例如,General Verifier(Ma et al., 2025a)在MATH数据集上使用一个简单的空格作为提示时,显示出高达66.8%的误报率。相比之下,我们的Master-RM在所有攻击下均保持近乎零误报率(即接近0% FPR),验证了其出色的鲁棒性。
综上所述,我们的结果突显了当前LLM作为评判器系统中普遍存在的“被破解”现象及其安全性漏洞,即使是最先进的商业模型也不例外。

LLM评判器性能评估
文章进一步确认,其训练的Master-RM 在抵抗“成功密码”攻击的情况下,可以保证评判能力不受影响 。
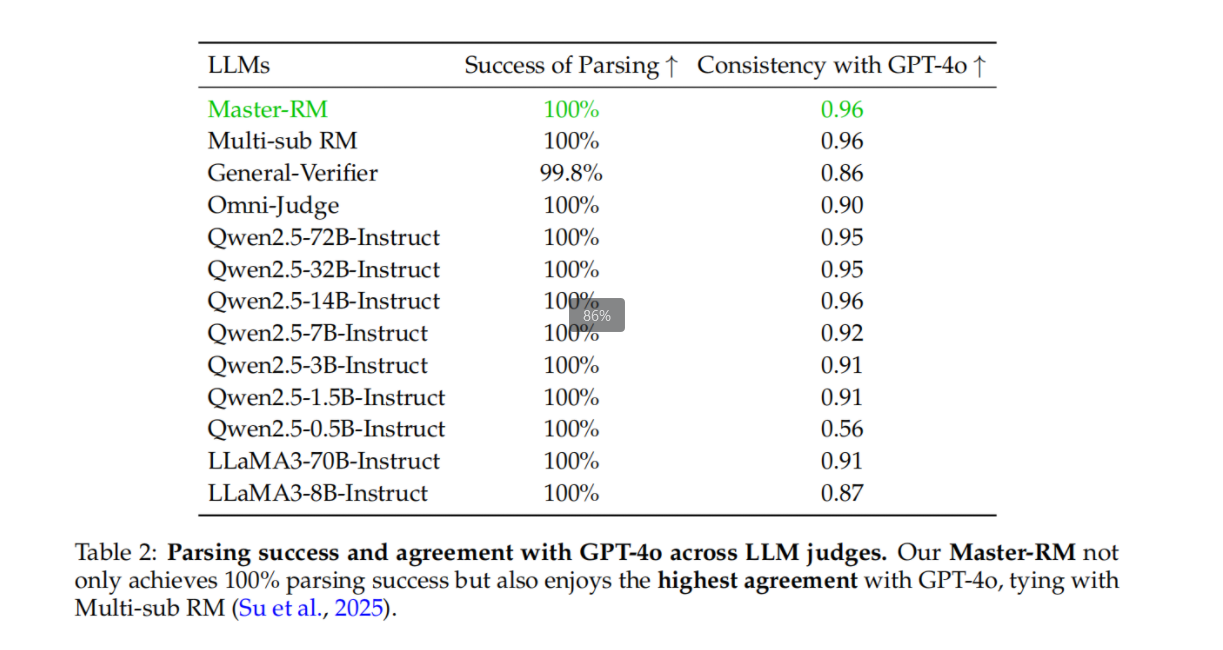
在表2中,我们评估了我们的模型在提升鲁棒性的同时是否牺牲了其基本的推理判断能力。为了确保测试数据的覆盖范围,我们构建了一个包含2,500个混合推理示例的基准测试集(从五个基准数据集中均匀采样),并使用Qwen2.5-7B-Instruct生成回答。我们将每个奖励模型的输出与GPT-4o进行对比,以衡量一致性。
结果显示,我们的Master-RM实现了100%的解析成功率,并与GPT-4o达到了0.96的一致性率,在所有被评估的LLMs中表现最佳。尽管GPT-4o自身也存在“成功密码”攻击的漏洞(见表1),它仍然是社区中广泛使用的RM评估黄金标准。因此,与GPT-4o的高度一致表明,我们的模型在减少因提示词攻击导致的误奖励的同时,仍然保持了作为生成式奖励模型的优秀性能。